PS. Т.к. здесь не сильно оптимизировано MTE обратно 1в1 думаю не получалось у людей собрать, но словарь же вытаскивали и делали это правильно. Проверить в данном случае можно просто присвоив каждому коду то, что было в MTE, не используя МТЕ: Пример для ОоА
Средствами электронных таблиц подобное делается практически мгновенно... Вытащить и собрать, увидеть что неправильно в плагине и допилить его, когда будет выниматься и вставляться 1в1 можно считать плагин правильным и возвращаться обратно к МТЕ. (Интересный получится плагин, если напишется... (здесь MTE нужно делать в плагине))
Расположение текстовых указателей и языков во всех оракулах. OoS U 071C00-084E04 FCFE2: 1C823300 - 073382 1txt_lang1 1C823300 - 073382 1txt_lang1 1C823300 - 073382 1txt_lang1 1C823300 - 073382 1txt_lang1 1C823300 - 073382 1txt_lang1 1C823300 - 073382 1txt_lang1
Рассмотрим испанский вариант OoA без МТЕ, для выявления второго двойного дна данной кроличьей норы. Первым исчез кончик его хвоста, а последней – улыбка; она долго парила в воздухе, когда все остальное уже пропало. – Д-да! – подумала Алиса. – Видала я котов без улыбок, но улыбкабезкота! (Ц)
Но пришёл ReCom и всех нас спас!
Т.е. получается конец строки обозначает байт 00 и байты 07xx. Эхо становится более похожим на оригинальное, но всё же остаются те же грабли... (можно конечно удалить лишние указатели, но это неправильно)
Дата: Понедельник, 25.08.2014, 15:57 | Сообщение # 152
Зора
Группа: Пользователи
Сообщений: 218
Статус: Оффлайн
Цитата
Ну дык, он же Зельд не фанат )
Тут не в том дело фанат-не фанат. Надоело оно ему всё. Я вообще удивлён, что на форуме Ш новичкам необразованным отвечаются ответы без нервов и с советами. Ganondorf doesn't use the Internet because there are too many Link's.
Дата: Четверг, 02.07.2015, 14:53 | Сообщение # 156
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
Всем привет. Немного помучившись я узнал в чем ошибка проекта. Тут даже не самого проекта ошибка а алгоритма поиска слов в МТЕ Круптара. И если написать функцию GetData в плагине то с костылем но все заработает, я думаю. Я могу написать плагин, но мне нужен человечек знакомый с этим есть пара вопросов. Как получить символ из загруженной строки в плагине (именно символ который в текстовике, а не его выходной код). И как записывать коды полученные из внешнего файла в выходной поток. Просто документации на круптар как бы вообще нет, поэтому и вопросы. Если кому интересно как я нашел ошибки то в аттаче скрин разбора и тестовик.
Дата: Четверг, 02.07.2015, 21:21 | Сообщение # 161
Горон
Группа: Пользователи
Сообщений: 187
Статус: Оффлайн
ЦитатаSlam ()
Всем привет. Немного помучившись я узнал в чем ошибка проекта. Тут даже не самого проекта ошибка а алгоритма поиска слов в МТЕ Круптара. И если написать функцию GetData в плагине то с костылем но все заработает, я думаю. Я могу написать плагин, но мне нужен человечек знакомый с этим есть пара вопросов.
Slam ты только не пропадай оставь на сайте эл. почту или скайп для связи - если есть шанс перевести Оракулов - то это было бы очень значимо для серии и для всех, потому что, очень интересное и запутанное путешествие и перевод им просто необходим для понимания и комфортной игры. И если немного позже Фокс появится что бы можно было связаться. И от себя добавлю не бросай начатое - к сожалению не могу помочь ответом на твои вопросы, но буду следить за процессом перевода и буду рад если получится разобраться.
Дата: Четверг, 02.07.2015, 21:52 | Сообщение # 162
Triforce keeper
Группа: Администраторы
Сообщений: 8940
Статус: Оффлайн
ЦитатаSlam ()
а пока на форуме magicteam спросил. Может там подскажут, Круптар ведь их разработка.
Там чет все повымирали... я там спрашивал насчет как пересчитать размер диалога (байты после пойнтера) средствами круптара - тишина уже х.з сколько... (Игра - Окарина 3Д). Проблема решилась отдельной утилитой. Костыль, конечно, но помогло и все работает. (Kosmos, если ты это читаешь - низкий поклон!)
Дата: Четверг, 02.07.2015, 23:21 | Сообщение # 163
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
KRATOR7, Ну я пропадать не буду, потому что сам долго следил за темой (мыло slam9191@gmail.com , правда сам захожу редко туда, но захожу). Сейчас просто отпуск выпал, решил разобраться в чем проблема, если не чего не выйдет придется тоже отдельную программу писать, для вставки текста обратно в РОМ.
Anton, Ну я пока по форумам групп переводов лазаю читаю, вдруг какое решение найдется там.
Только я переводить не буду, сразу оговорюсь, могу только подготовить к переводу проект. У меня с русским то плохо, а про английский вообще говорить не приходится.
Дата: Пятница, 03.07.2015, 01:04 | Сообщение # 164
Горон
Группа: Пользователи
Сообщений: 187
Статус: Оффлайн
ЦитатаSlam ()
Только я переводить не буду, сразу оговорюсь, могу только подготовить к переводу проект. У меня с русским то плохо, а про английский вообще говорить не приходится.
Если будет готовая программа по редактированию перевода - то я думаю что найдутся люди для перевода. Даже я готов попробовать - естественно под руководством Антона. Главное с программой перевода разобраться, а дальше уже дело будет продвигаться легче. Там вроде как уже пробовали переводить и даже частичный проект был но там всё время какие то ошибки получались поэтому наверное лучше с нуля начинать. Если нужно могу скинуть файлы - они есть где то в постах выше.
Сообщение отредактировал KRATOR7 - Пятница, 03.07.2015, 01:05
Дата: Пятница, 03.07.2015, 12:09 | Сообщение # 168
Зора
Группа: Пользователи
Сообщений: 271
Статус: Оффлайн
Помнится Фокс вроде в европейке вытащил, чтобы французский язык можно было переводить. Он там без МТЕ. Но в июне почему-то этот проект удалил с форума...
Дата: Пятница, 03.07.2015, 22:54 | Сообщение # 170
Горон
Группа: Пользователи
Сообщений: 187
Статус: Оффлайн
Если кому нибудь поможет здесь всё что мне удалось нарыть по переводу оракулов - там голосарий, частично вытащенная графика в папках и португальский перевод без МТЕ, вытащенный дамп текста в папке chief net (не знаю насколько актуальный, но что бы начать переводить должно быть достаточно)
Там много "мусора" но уверен что есть и полезные файлы которые могут пригодится. Мне кажется стоит начать с перевода предметов и локаций - это в любом случае будет не лишним. В первом посте можно будет редактировать. В ссылке на файлы есть пару голоссариев от других людей - может стоит объединить и выбрать лучшее?
Сообщение отредактировал KRATOR7 - Пятница, 03.07.2015, 23:31
Дата: Суббота, 04.07.2015, 12:05 | Сообщение # 171
Зора
Группа: Пользователи
Сообщений: 379
Статус: Оффлайн
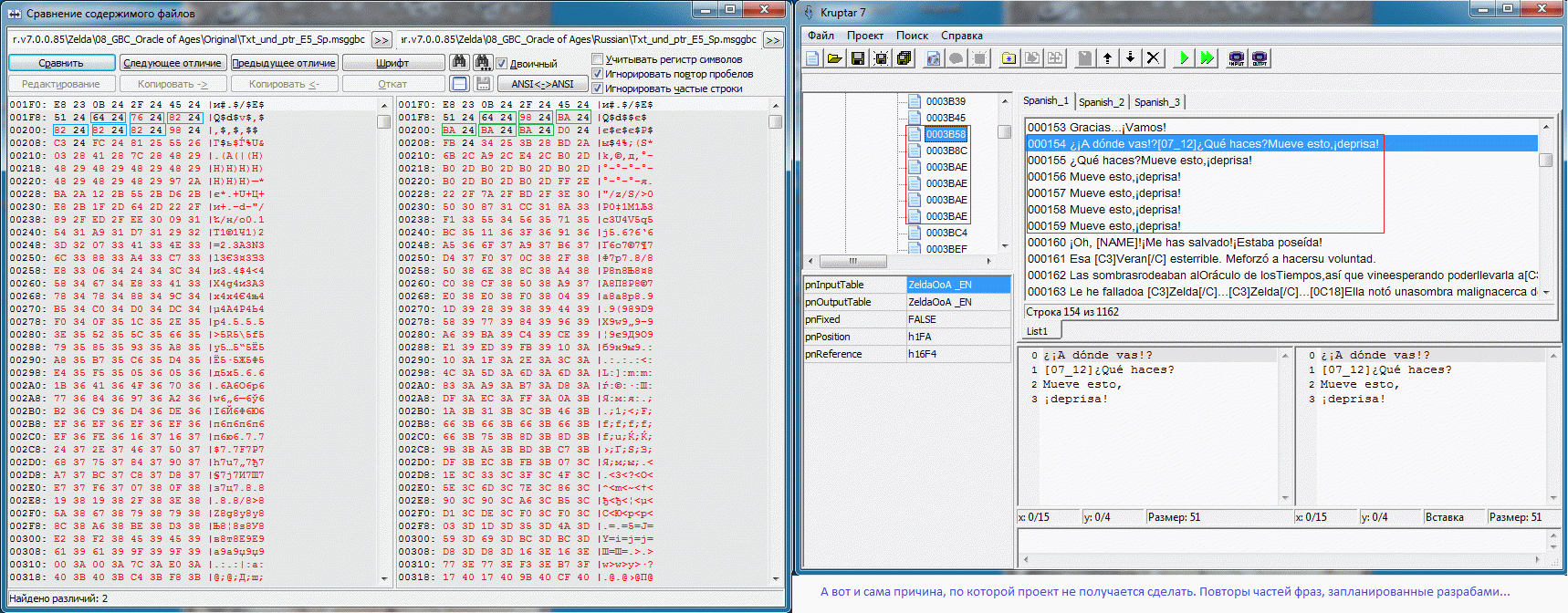
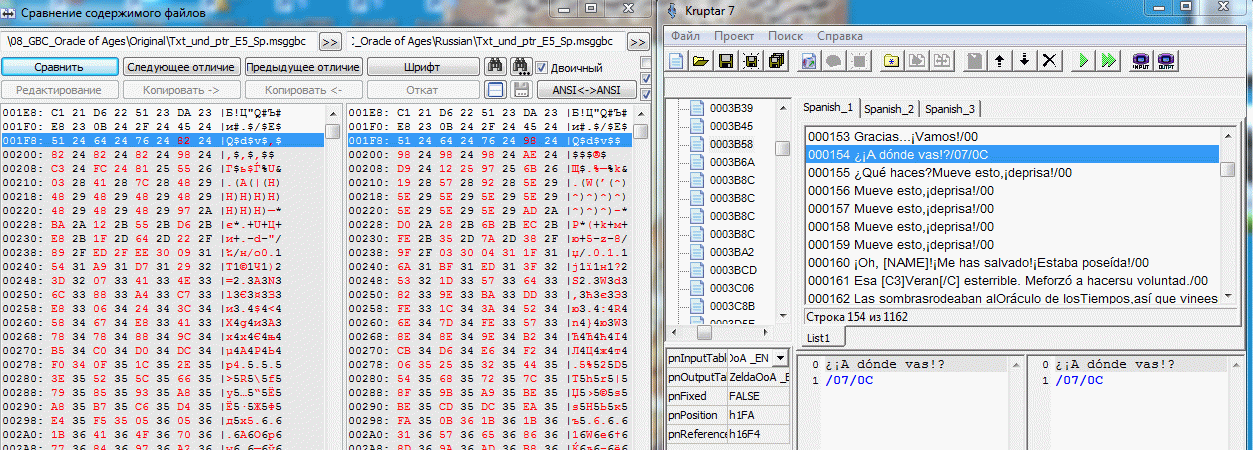
Удалилось, вернее не поместилось только для Wii 3DS DSi и WiiU экселька, таблицы и плагин, так как экселька выросла в процессе эволюции и теперь её нужно разделить на две для Wii WiiU и межмирного из 3DS с плагином и для остальной 3DS и DSi без плагина. Так как стали понятны все шрифты и составление таблиц по ним сильно упростилось, кому интересно в скриптории обновился файлик (для составления таблиц используется именно он). А по поводу Оракулов здесь не совсем в MTE проблема. Плагин для такого вида MTE есть в исходниках на сайте магиков. Основная проблема в том как эхо(последний спойлер с картинками из круптара и сравнение с оригиналом) понимать и если нужно как его повторить. Пример для испанского текста рассмотрен, в английском это было хуже видно т.к. МТЕ, но такая фигня во всех языках и в обоих оракулах. А для графики из проги распаковщик можно вытащить(или тут почитать как она запакована) + в том же сообщении(где эхо) есть ссылка на сами эти куски(ссылки в самом низу) и различные другие LZ пакеры. (Вернулся ReCom, нашлись и пакеры)
Дата: Суббота, 04.07.2015, 15:03 | Сообщение # 172
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
FoX_XoF, То есть основная проблема в этих повторяющихся байтах (24) и первом (64 24) или есть еще какие то? Просто я этого не увидел сразу то. Если все коды такие, то может есть идейка.
Добавлено (04.07.2015, 15:03) --------------------------------------------- И кстати, а с самим Рекомом не кто не пробовал связаться? У него же ICQ в профиле на форуме, через ICQ легко находиться его страничка вк. Просто может у него остались исходники распаковщика/запакощика. Вдруг поделится
Дата: Суббота, 04.07.2015, 15:08 | Сообщение # 173
Зора
Группа: Пользователи
Сообщений: 379
Статус: Оффлайн
Slam, Это указатели(64 24 и т.д.) Там просто сравнил оригинал и пересобранный оригинальный текст и показал что и почему идёт не так. Это первое место где замечено такое(в английском это было сложнее увидеть т.к. MTE-коды затрудняют чтение самой фразы, но там точно такая же фигня с указателями). Дальше - больше. Т.е. они указывают на часть текста уже указанного предыдущим указателем и заканчивающуюся символом конца строки. Т.е. строка одна и хранится она как одна, а вот подуказателей на её части может быть много(а круптар каждую такую часть запишет ещё раз отдельно и каждый раз с байтом окончания строки, на картинке же видно что строка всего одна и байт окончания её тоже один, но вот ссылаются на неё: один раз целиком, один раз после кода [07_12] и четыре раза после вопросительного знака который идёт после этого кода) (а вот это ещё вопрос). Мест таких много и указатели коды (всегда 07xx) и знаки окончания предложения(точка, восклицательный, вопросительный и т.д.) там естественно свои. Просто непонятна логика разработчиков: как это сделано и зачем... Идея настолько глупа, банальна и наляписта, но...(Ц)
Сообщение отредактировал FoX_XoF - Пятница, 17.07.2015, 17:02
Дата: Суббота, 04.07.2015, 16:50 | Сообщение # 174
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
FoX_XoF, Действительно странно это. Зачем такой огород городить. Если с эти разбираться, то скорее всего придётся свою программу писать для выдирания и вставки текста. Которая будет проверять каждую строку с предыдущей, и искать в предыдущей ту которую нужно записать. Если строка найдена в части предыдущей то её записывать не нужно, необходимо только указатель подправить.Правильно думаю?
Добавлено (04.07.2015, 16:02) --------------------------------------------- Либо в плагине к Круптару попытаться это реализовать. Как то так: 1) самую первую строчку точно пишем в РОМ, а проверять начинаем со второй; 2) каждую строчку пишем во временную строку для сравнения; 3) сравниваем каждую строчку со временной (которая обновляется каждый шаг, то есть всегда равна - строка полученная плагином от круптара минус 1); 4) если совпадение найдено строку не пишем меняем только поинтер; 5) если совпадений нет пишем строку В РОМ.
Ну у меня только такие идеи, и это будет работать только с той частью функции GetData, где нормально пишется МТЕ.
Добавлено (04.07.2015, 16:50) --------------------------------------------- Еще вспомнил, что это не должно работать для таблицы МТЕ, то есть ее нужно как то опознать и пропустить, чтобы работал этот скрипт только с текстовой частью РОМа. Тут вопрос, тогда, как опазнать ту группу где хранится МТЕ? Может вместе с тобой и получится расхакать эту игру.
Дата: Воскресенье, 05.07.2015, 14:16 | Сообщение # 176
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
FoX_XoF, Если я думаю правильно, то придется править код Круптара. Во первых подпрограмму GetData переделать из функции в процедуру, чтобы появились выходные параметры новые, для передачи адреса и поинтера в код пересчета, и входные в виде адреса и поинтера. Во вторых работу со словарем оптимизировать под наш случай, просто плохо представляю, как сделать замену слов на коды МТЕ без костыля (достаточно глянуть на входные параметры GetData в плагине).
Сейчас опишу работу костыля, чтобы не забыть (для себя в частности, мало ли не выйдет оптимизировать работу словаря): 1) так как в подпрограмму приходит строка уже с замененными кодами из словаря, необходимо чтобы в свойствах группы словарь был без МТЕ (т.е. присылал коды букв), для избежания белиберды; 2) пишется программа-костыль, которая изменяет слова из МТЕ на коды букв в этом слове. в соответствии с нашей кодировкой, и записывает их в файл типа byte (у меня она уже написана почти, то есть в текстовый файл коды уже пишутся правильно, осталось только перевести их в тип byte); 3) в функции GetData каждая новая вторая строка проверяется на соответствие строке в файле полученном из костыля; 4) записывается в выходной поток код МТЕ из нашего файла костыля, а указатель на буквы входной строки увеличивается на длину строки МТЕ из файла;
Дата: Воскресенье, 05.07.2015, 14:37 | Сообщение # 177
Горон
Группа: Пользователи
Сообщений: 187
Статус: Оффлайн
ЦитатаSlam ()
Сейчас опишу работу костыля, чтобы не забыть (для себя в частности, мало ли не выйдет оптимизировать работу словаря): 1) так как в подпрограмму приходит строка уже с замененными кодами из словаря, необходимо чтобы в свойствах группы словарь был без МТЕ (т.е. присылал коды букв), для избежания белиберды; 2) пишется программа-костыль, которая изменяет слова из МТЕ на коды букв в этом слове. в соответствии с нашей кодировкой, и записывает их в файл типа byte (у меня она уже написана почти, то есть в текстовый файл коды уже пишутся правильно, осталось только перевести их в тип byte); 3) в функции GetData каждая новая вторая строка проверяется на соответствие строке в файле полученном из костыля; 4) записывается в выходной поток код МТЕ из нашего файла костыля, а указатель на буквы входной строки увеличивается на длину строки МТЕ из файла;
Вот это сложности получаются. А не проще будет использовать версию без MTE с португальским языком. Если есть вытащенный текст на английском то вопрос будет только в правильной подстановке фраз на нужные места с последующей заменой на русский?
Дата: Воскресенье, 05.07.2015, 15:03 | Сообщение # 178
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
KRATOR7, Текст то нормально вытаскивается. Ну проще то проще только вот с МТЕ раздолье для перевода гораздо больше. Переводчикам будет проще работать, не заморачиваясь с фразами.
Дата: Воскресенье, 05.07.2015, 20:54 | Сообщение # 180
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
Anton, Ну сами посудите, слово в МТЕ в любом случае занимает 2 байта кода (указатель на слово) и не важно сколько символов в этом слове. Теперь обратная ситуация в текстовой части место ограниченно и если не использовать МТЕ, то часто встречающееся слово состоящее, например, из 5ти символов (5 байт) будет постоянно занимать 5 байт, а если оно есть в МТЕ то занимает всего лишь 2 байта в текстовой части. А если таких слов несколько? простая математика говорит, что выгода очевидна.
Дата: Воскресенье, 05.07.2015, 21:57 | Сообщение # 181
Зора
Группа: Пользователи
Сообщений: 379
Статус: Оффлайн
Slam, в MTE есть одинаковые куски. 02xx 03xx 04xx 05xx делались разрабами каждый отдельно(может быть даже на разные части текста, это я уже забыл, и потому в них иногда встречаются одинаковые сочетания), тут мне тоже логика не совсем понятна, но может это оттого, что я не шарю в методах оптимизации. А в коде Круптара не каждый Джинн разберётся без бутылки... Примеры: 123 + у меня до сих пор не получилось его скомпилировать в стареньком 7 дельфи, после победы над одними зависимостями обнаруживаются всё новые и в итоге побеждает лень... (кончились зависимости, пошли отсутствующие функции) Там есть некоторые недоработки, которые так ими и остались, хотя может быть это оттого, что я и в круптаре тоже не очень шарю, так как когда-то пробовал сделать проект с MTE средствами реализованными в Круптаре и что-то там шло явно не так.(байт переноса) Но люди писали и довольно сложные плагины со всякими распаковками и запаковками не меняя при этом код круптара. Вот нашёл пример плагина для игры с MTE в исходниках.
Function GetData(TextStrings: PTextStrings): AnsiString; stdcall; Var R: PTextString; MTELengthOffset: Integer; begin Result := ''; If TextStrings = NIL then Exit; With TextStrings^ do begin R := Root; MTELengthOffset := $4833E; While R <> NIL do begin ROM [MTELengthOffset]:= Length(R.Str); Inc(MTELengthOffset); Result := Result + R^.Str; R := R^.Next; end; end; end;
function GetStrings(X, Sz: Integer): PTextStrings; stdcall; var MY: Byte; I, LEN, MTELengthOffset: Integer; Wrd: PTextString; begin Result := NIL; If (X >= RomSize) or (X < 0) then Exit; New(Result, Init); MTELengthOffset := $4833E; Wrd := Result.Add; I := 0; LEN := ROM[MTELengthOffset]; //считываем длину первого слова while I < Sz do // пока I меньше количества фраз в блоке делаем дела begin MY := ROM[X]; //считываем символ из рома Inc(X); //увеличиваем позицию в роме на один Dec(LEN); //уменьшаем длину на 1 байт, так как один байт мы считали Wrd.Str := Wrd.Str + Char(MY); // если символ не ссылка на дте, то просто записываем его if LEN = 0 then begin if I < Sz - 1 then Wrd := Result.Add; //добавляем новое слово в массив слов Inc(I); //если слово полностью считали, то увеличиваем индекс цикла Inc(MTELengthOffset); //увеличиваем индекс длин LEN := ROM[MTELengthOffset]; //считываем новую длину end; end; end;
Function GetData(TextStrings: PTextStrings): AnsiString; stdcall; Var R: PTextString; begin Result := ''; If TextStrings = NIL then Exit; With TextStrings^ do begin R := Root; While R <> NIL do with R^ do begin if (Str <> '') and (Byte(Str[Length(Str)]) >= $F6) then Result := Result + Str else Result := Result + Str + #$C4; R := Next; end; end; end;
Function GetStrings(X, Sz: LongInt): PTextStrings; stdcall; Var MY: byte; I: Integer; Wrd: PTextString; begin Result := NIL; If (X >= RomSize) or (X < 0) then Exit; New(Result, Init); Wrd := Result.Add; I := 0; //начальное значения индекса цикла while I < Sz do // пока I меньше количества фраз в блоке делаем дела begin MY := ROM[X]; //считываем символ из рома Inc(X); //увеличиваем позицию в роме на один if MY <> $C4 then Wrd.Str := Wrd.Str + Char(MY); if MY in [$C4, $F6..$FB] then begin Inc(I); //если символ равен коду окончания фразы, то увеличиваем индекс цикла if I < Sz then Wrd := Result.Add; end; end; end;
Также пытался вытащить в отдельный файл весь английский текст без всякой MTE, но и там какие-то косяки возникали то с пропуском чего-то нужного, то с повторами чего-то ненужного. Потому и стал смотреть другие языки(в которых от MTE остались лишь рудиментарные признаки в виде нескольких целых слов). Нашёл "эхо" и стал читать доки по железу GB/GBC (плохо видать читал), зачем-то же они его делали(Есть конечно вероятность что они были пьяны и потому не смогли разобраться в том что сами понаписали и запилить третью часть серии.). Но пока лень побеждает...
+ Корейские переводы сделаны для расширенных до двух метров ромов, на свободном месте.
Дата: Воскресенье, 05.07.2015, 22:40 | Сообщение # 182
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
FoX_XoF, Эти МТЕ видимо не подойдут, первый для слов с фиксированной длинной (ну наподобие МТЕ у NES там длинна слова 2 байта), а второй если перед МТЕ словом стоят управляющие байты. В нашем случае это мало подходит, а вот как корейцы запилили на пустое место интересно посмотреть. Люди писали я смотрел не спорю, была бы дока нормальная, хотя бы на плагин, было бы проще. Но если делать плагин для поиска МТЕ слов, в нашем случае, алгоритм подойдет тот который я описал не меняя кода круптара. А вот как в фунцию передать адрес строки, ее поинтер, и главное обновленные вынести из функции я ума не приложу, без документации. Проще будет попробовать скомпилировать круптар и там уже изменить входные/выходные параметры подпрограммы.
Добавлено (05.07.2015, 22:25) --------------------------------------------- FoX_XoF, А насчет Круптара и бутылки - это да. Похоже прийдется пару-тройку знакомых прогеров поднапрячь (учились в смежных группах я на электронике они на прогеров, только я 3 года работал по своей специальность и к коду не притрагивался, а они кодили как раз на делфи). Вдруг при помощи этой самой бутылки они разберутся в коде.
Добавлено (05.07.2015, 22:40) --------------------------------------------- Кстати вот тут http://romhacking.ru/news....24-2945 человек с ником DrMefistO пишет, что круптар нормально компилится на DElphi XE7 нужно скачать попробовать, а вдруг.
Дата: Понедельник, 06.07.2015, 02:04 | Сообщение # 183
Горон
Группа: Пользователи
Сообщений: 187
Статус: Оффлайн
ЦитатаSlam ()
Ну сами посудите, слово в МТЕ в любом случае занимает 2 байта кода (указатель на слово) и не важно сколько символов в этом слове. Теперь обратная ситуация в текстовой части место ограниченно и если не использовать МТЕ, то часто встречающееся слово состоящее, например, из 5ти символов (5 байт) будет постоянно занимать 5 байт, а если оно есть в МТЕ то занимает всего лишь 2 байта в текстовой части. А если таких слов несколько? простая математика говорит, что выгода очевидна.
Согласен что в программном варианте для запуска на оригинальном железе лучше (нужен гейм бой колор и флеш картридж для записи рома -стоит в три раза дороже приставки), но для запуска на эмуляторе неважен размер файла (а почти все сейчас предпочтут проходить именно на эмуляторах там графика сглаженней и устройство любое подойдет от мобилки до пк и псп) поэтому если сам вопрос так труднорешаем - то может стоит пойти путём наименьшего сопротивления и просто перевести португальский ром без МТЕ на английский а потом на русский главное что бы сам ром работал без глюков. Slam обязательно попробуй свой способ с умными людьми, но если не получится попробуй более простой способ без МТЕ.
Дата: Понедельник, 06.07.2015, 14:19 | Сообщение # 184
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
KRATOR7, Да с МТЕ то пол беды, там проблема хоть и есть, но решаема. Насчет записи в пустое место нужно тоже почитать. Я боялся что двух байтовых поинтеров не хватит, для указания в пустое место, но раз корейцы как то сделали, то можно и попробовать повторить. Тут проблема в другом, на нее указал Fox, несколько постов выше. В круптаре есть функция SeekSame, которая и должна решать эту проблему, но ее нужно допиливать под наши нужды, а этого без разбора кода круптара невозможно.
Дата: Вторник, 07.07.2015, 20:09 | Сообщение # 185
Зора
Группа: Пользователи
Сообщений: 379
Статус: Оффлайн
ЦитатаSlam ()
Я боялся что двух байтовых поинтеров не хватит, для указания в пустое место
Они двойные(ptr2ptr) одни двубайтовые указатели указывают на другие двубайтовые указатели. (это сто первых указателей).
ЦитатаSlam ()
В круптаре есть функция SeekSame
Да, там по полной программе эта функция у разрабов задействована, т.е одинаковых указателей ссылающихся на одну строку много, но видимо у них она была более продвинутая и её действительно нужно допиливать... (руки мне нужно допиливать тоже)
Да, но словарь русских слов в переведенной версии, может быть больше словаря в оригинале, ввиду особенности русского языка. Иногда доходит до того, что словарь просто не влазит в РОМ и приходится изголяться -- бить слово на слоги и их пхать в словарь, например, или пихать в словарь слово без окончания, а окончание лепить уже буквами. Не все так однозначно, карочи. Ganondorf doesn't use the Internet because there are too many Link's.
Дата: Четверг, 09.07.2015, 22:23 | Сообщение # 188
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
Сегодня Djinn поправил сборщик Круптара, и я смог собрать его. В версии с исходников пересчёт прошёл нормально. Только там какая то ерунда с адресами (после пересчёта они идут не по порядку) я скрины скинул в тему Круптара на форуме Меджиков.
Дата: Четверг, 23.07.2015, 11:31 | Сообщение # 190
Зора
Группа: Пользователи
Сообщений: 379
Статус: Оффлайн
ЦитатаKRATOR7 ()
Я так понимаю там половину круптара нужно переделать.
Он как раз этим и занимается, т.е. выкачал из репозитория старые версии 7.0.0.85 "с нумерацией строк" и 7.1.1.10 без "особой сортировки" , разобрал код и добавил к нему комментарии, а теперь допиливает то, чего там не хватало, т.к. плагинами Оракулы оказалось невозможно правильно победить.
ЦитатаKRATOR7 ()
есть какие нибудь продвижения
ReCom вернулся.
Он разобрал Сезоны и сделал программу для работы с ними, при незначительном изменении (изменение нескольких указателей) она будет работать и с Эпохами, т.к. всё идентично. Также у него сохранились программы для извлечения и запаковки графики. Т.е. переводы обоих Оракулов таки определённо обещают быть.
Дата: Четверг, 23.07.2015, 11:57 | Сообщение # 191
Деку
Группа: Пользователи
Сообщений: 34
Статус: Оффлайн
KRATOR7, С самим переводом каких-то особых продвижений нет. Я сейчас делаю более гибкий Круптар, потому что стандартный не подходит оракулам. Например, теперь тот кто пишет плагин может кодировать строку символами (ну из таблицы круптара), непосредственно в плагине, я перенес эту часть из кода программы. Теперь решится вопрос с МТЕ в оракулах (и других играх где круптар не правильно отрабатывал). А дальше нужно думать что и как выносить в плагин. Например У нс есть "эхо" в оракулах, которое тоже нужно решать.
Дата: Пятница, 24.07.2015, 00:26 | Сообщение # 192
Горон
Группа: Пользователи
Сообщений: 187
Статус: Оффлайн
ЦитатаSlam ()
KRATOR7, С самим переводом каких-то особых продвижений нет. Я сейчас делаю более гибкий Круптар, потому что стандартный не подходит оракулам. Например, теперь тот кто пишет плагин может кодировать строку символами (ну из таблицы круптара), непосредственно в плагине, я перенес эту часть из кода программы. Теперь решится вопрос с МТЕ в оракулах (и других играх где круптар не правильно отрабатывал). А дальше нужно думать что и как выносить в плагин. Например У нс есть "эхо" в оракулах, которое тоже нужно решать.
ЦитатаFoX_XoF ()
ReCom вернулся.
Он разобрал Сезоны и сделал программу для работы с ними, при незначительном изменении (изменение нескольких указателей) она будет работать и с Эпохами, т.к. всё идентично. Так же у него сохранились программы для извлечения и запаковки графики. Т.е. переводы обоих Оракулов таки определённо обещают быть.
Спасибо порадовали - самое главное что процесс идёт , желаю вам много терпения и знайте что всё что вы делаете-это важно, этого очень ждут и искренне вас поддерживают (ну хотя бы морально) много людей. Буду стараться помогать по мере своих возможостей.
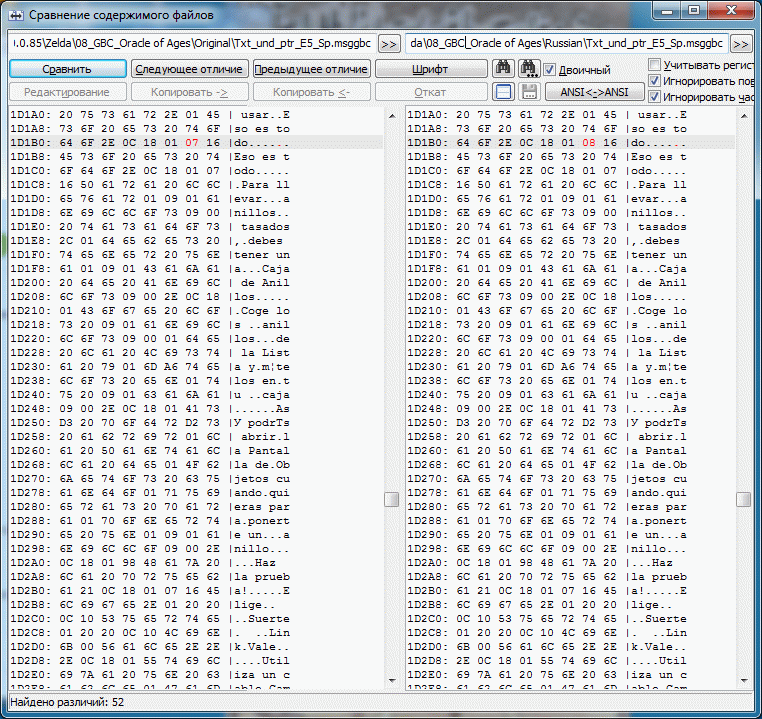
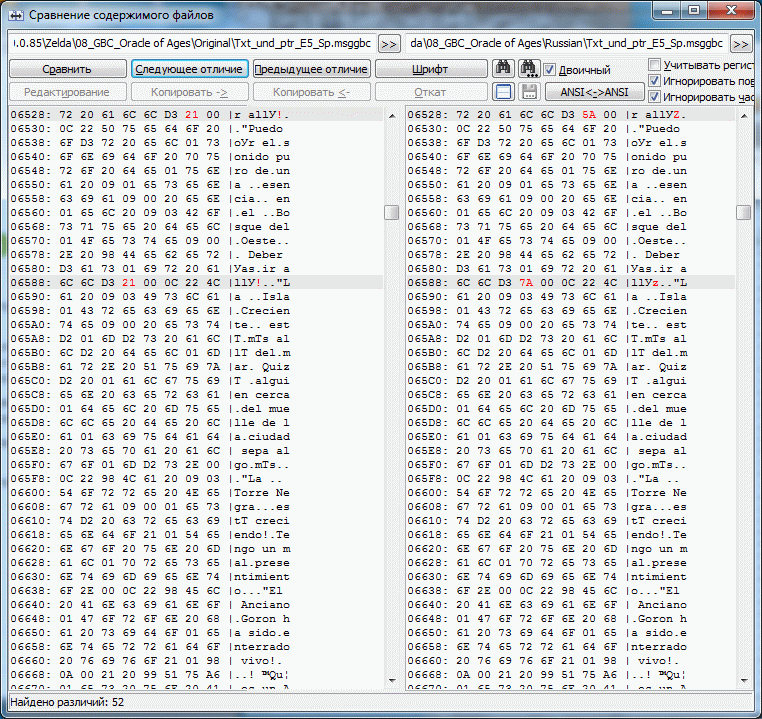
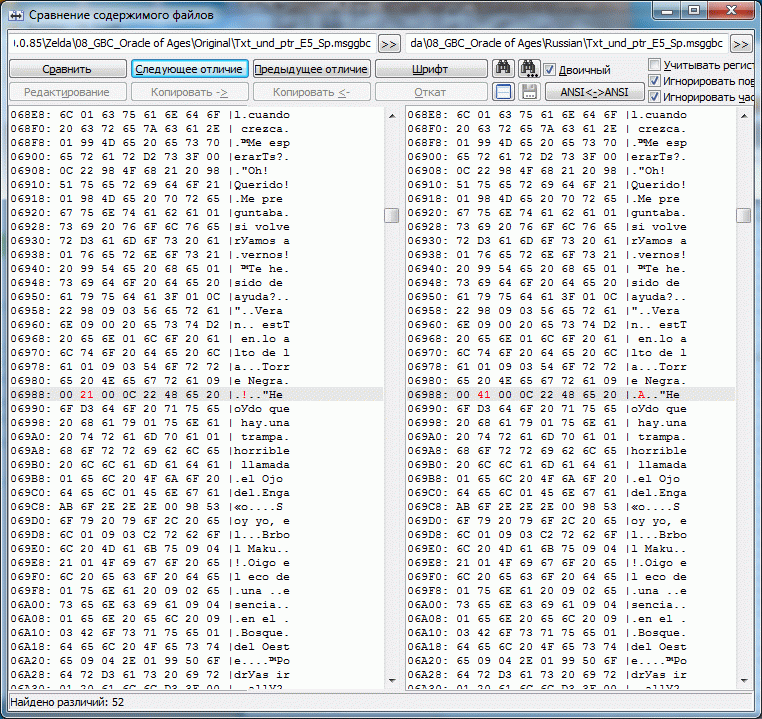
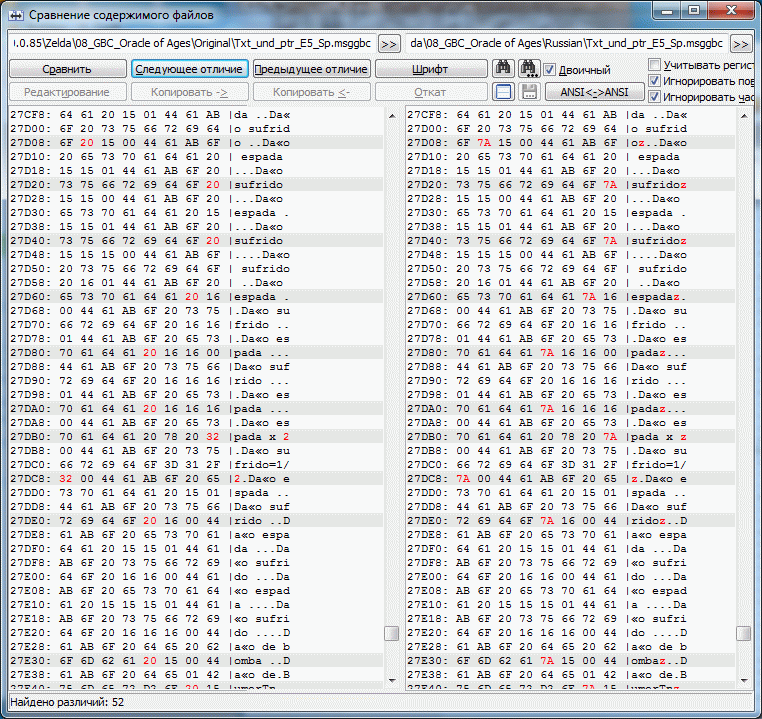
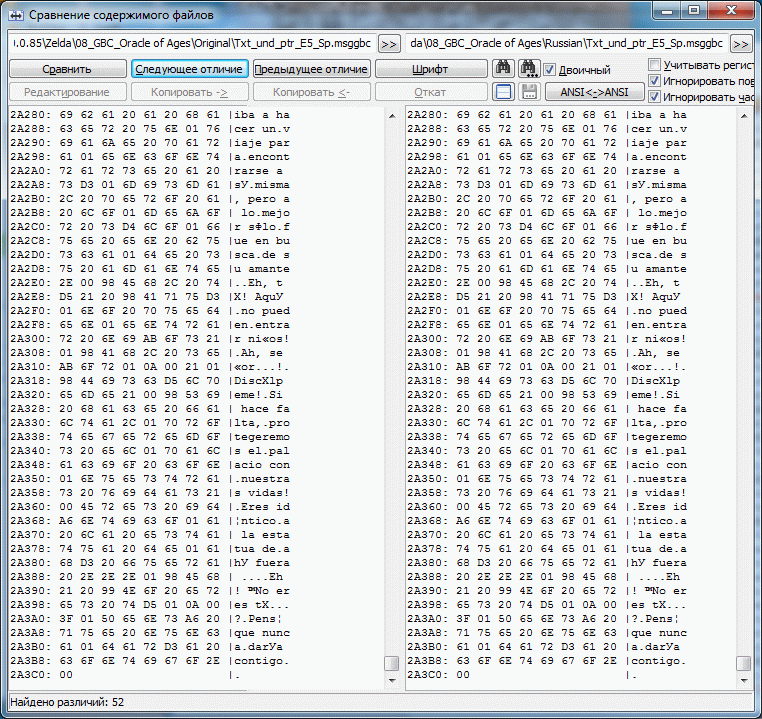
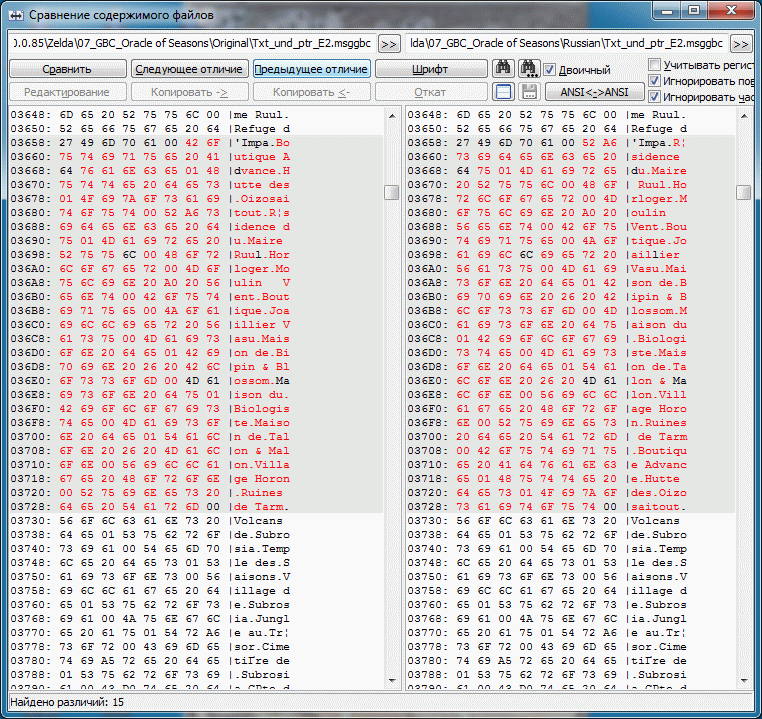
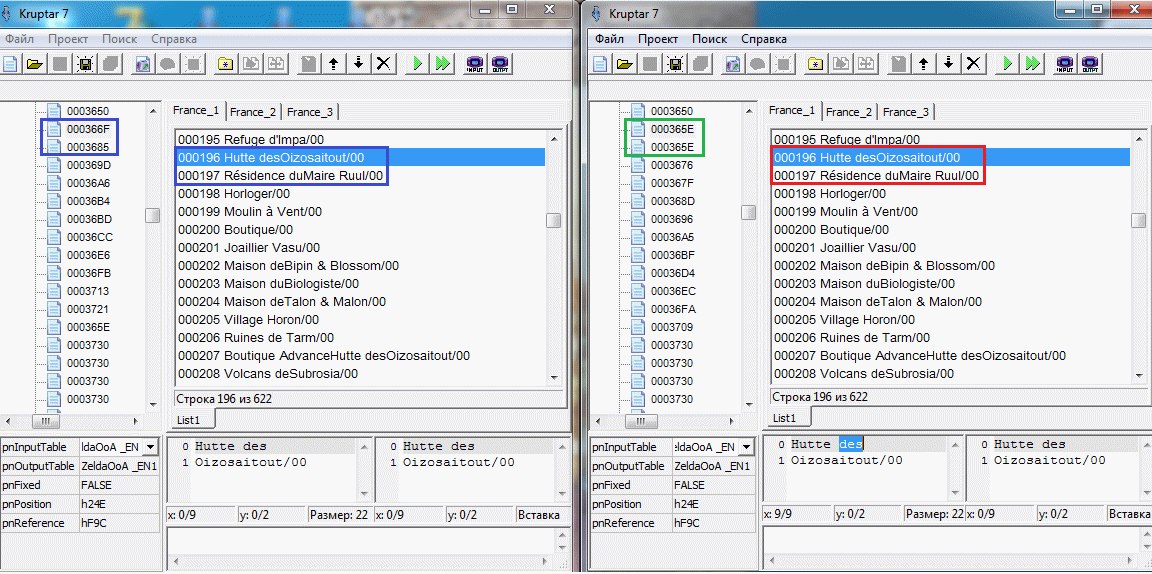
Пример проекта OoA для испанского языка, в котором МТЕ - рудимент. Чтобы оценить правильность работы Круптара и плагина(сложение 1в1) были подправлены некоторые строки. Если seekSame работает от начала и до конца большого блока(~64 кило) то появляется довольно много свободного места. В одном третьем блоке было доступно более килобайта. Можете сами догадаться какой хаос с указателями творится там где МТЕ таки есть. Конкретика: Указатель по адресу 15FE Указывал на пустую строку оканчивающуюся на 00, но так как у нас в этой группе уже был такой прецедент, seekSame этот ноль подрезал и соответственно все последующие строки смещались на байт, чтобы этого избежать и увидеть, а всё ли правильно дальше, добавил z к следующей строке. Итого 2 отличных от оригинальных указателя и довольно большое количество подправленных строк, т.к. оптимизировали разрабы весьма и весьма неоднозначно, seekSame(MTE-style) использовали весьма извращённо(чтобы это увидеть заменял в оригинальных строках последний знак на z, временами ещё и Z, в одном особо странном случае не хватило и их и появилась A) иногда даже (1D1B6 - первый скрин) могли оставить партак после сокращения строки. Либо это такие фишки GB/GBC и мы выясним это в процессе, либо разрабы всё же были пьяны.
Фокс сделает полноценный проект и можно будет переводить. Еще правда графику достать нужно и перерисовать.
И он таки сделал проекты. И даже уже перевёл обоих...
...правда с французского на английский, но всё же. Даже вставил русский перевод и нашёл косяки ReCom'a в сезонах, там действительно много переведено, но править и править ещё (надо как-то согласовать последние правки и с указателями на графику мне нужна помощь). Т.е. с текстом теперь всё хорошо, можно и в старом Круптаре 7.0.0.85 переводить, т.к. подсветка и быстрее, а оптимизировать уже только в самом конце в новой версии. Нашёл косячки и в оптимизирующем плагине для круптара 7.0.0.85/1.
Ну и уронил его естественно, как же без этого.
ReCom,
Вот пример выхода за 16 символов в строке. Прилепил тексты, чтобы можно было увидеть различия американского и английского и проекты. В круптаре гораздо удобнее переводить, а чтобы вставлять потом в американки, таки понадобится MTE, а вот в европейках можно и с не оптимизированным текстом отлично работать. (именно это я имел в виду, когда говорил про место для текста). Но, так же можно оптимизировать строки этой версией.
Дата: Четверг, 13.08.2015, 11:35 | Сообщение # 197
Миниш
Группа: Пользователи
Сообщений: 6
Статус: Оффлайн
FoX_XoF, сравнил американский и английский тексты: разницы почти никакой, разве что только в U-версии кое-где не доглядели и забыли выделить цветом некоторые имена и названия, кое-где имеются орфографические ошибки, которые исправлены в E-версии. Правда, существенно различаются диалоги с 978 по 989 - неясно, для чего они нужны, в игре я их нигде не встречал. Ещё в E-версии информативно дополнены некоторые предложения, например, там, где птица рассказывает про меню сохранения: оказывается, открыть его ещё можно, нажав одновременно Select и Start. Ну и несколько других мелких различий, таких как Dungeon/Maze, Santa/chimney sweep. В U-версии на табличке: "Добро пожаловать, Санта!" В E-версии: "Камины лучше всего горят в морозные дни! Ищу трубочиста."
Другие европейки пока не смотрел. Хорошо бы ещё с японской версии текст содрать, интересно взглянуть на оригинал.
Согласен, круптар - вещь довольно мощная и очень удобная, но я как-то привык работать по старинке, со своими программами. У меня РОМ американский, увеличен до 2 МБ, текст заливается автоматически во вторую часть РОМа без какой-либо оптимизации, так что с местом, повторюсь, никаких проблем вообще нет. Хотя, в принципе, если шрифты, которые болтаются над текстом, перенести куда-нибудь в другое место и довести оптимизатор до совершенства, можно попробовать уместить его на старом месте.
Насчёт 16 символов: может я где-то и не исправил - не беда. У меня в программе имеется функция подсчёта количества символов на строку, только я её временно отключил, чтобы не мешали вылезающие диалоговые окна с ошибкой. Перевести бы сначала всё, а эти дела можно оставить напоследок. Насчёт дефисов и тире согласен, надо бы везде исправить.
Дата: Четверг, 13.08.2015, 19:59 | Сообщение # 198
Зора
Группа: Пользователи
Сообщений: 379
Статус: Оффлайн
ЦитатаReCom ()
Хорошо бы ещё с японской версии текст содрать, интересно взглянуть на оригинал.
Там хитрая однобайтовая кодировка в японке, хотя... если удастся расшифровать все японские символы в шрифте, можно будет и на оригинал глянуть, коды видимо от 60 до FF получаются. + там есть такая же кнопочка переключения регистра алфавита как в европейке, в американке видел эти иероглифы, когда разбирался как графику искать, но сама функция видимо вырезана.
++ Ага, угадал. Но кроме каны ещё куча символов есть, уже двубайтовая 06xx. Зато теперь начальные символы в еврошрифтах стали понятны...
Страшная кандзи страшным шрифтом.
Если кто дополнит табличку 0600-0657, будет и японский текстдамп.
ЦитатаReCom ()
У меня РОМ американский, увеличен до 2 МБ, текст заливается автоматически во вторую часть РОМа без какой-либо оптимизации, так что с местом, повторюсь, никаких проблем вообще нет.
Ну... блин, я наверно плохо выражаю свою мысль. Там файлик в каком-то архиве должен быть 2block_test.txt В Сезонах то оно ещё нормально, а вот будешь переводить Эпохи(надеюсь), увидишь.